
Introduction
Data sits at the center of every modern corporate strategy. Global enterprises rely on sprawling data pipelines to feed machine learning models, automate supply chains, and guide critical executive decisions. Yet, as data environments grow into highly complex multi-cloud ecosystems, a major visibility gap has emerged. Many organizations struggle to explain where their data originates, how it transforms as it moves through internal systems, and who ultimately owns it.
Operating without an exact, verified history of your data introduces severe compliance risks, corrupts analytics accuracy, and degrades overall institutional trust. To solve this structural visibility bottleneck, enterprise technology teams are prioritizing data lineage as the foundational pillar of modern data governance.
Defining Data Lineage Architecture
Data lineage is the systematic tracking, documenting, and visual mapping of data elements as they move, change, and settle across an enterprise infrastructure. It provides data engineers, compliance officers, and business analysts with an unalterable audit trail of the entire data lifecycle.
Instead of looking at data as a static point inside a siloed database, data lineage treats information as a fluid pipeline. It provides clear, documented answers to high-stakes operational questions:
- Provenance: Exactly which database, IoT device, or third-party API generated this specific data point?
- Transformation: What specific SQL queries, Python scripts, or ETL (Extract, Transform, Load) pipelines altered the raw values before they hit the final report?
- Dependencies: Which downstream business intelligence dashboards or artificial intelligence systems will break if a software team alters an upstream database schema?
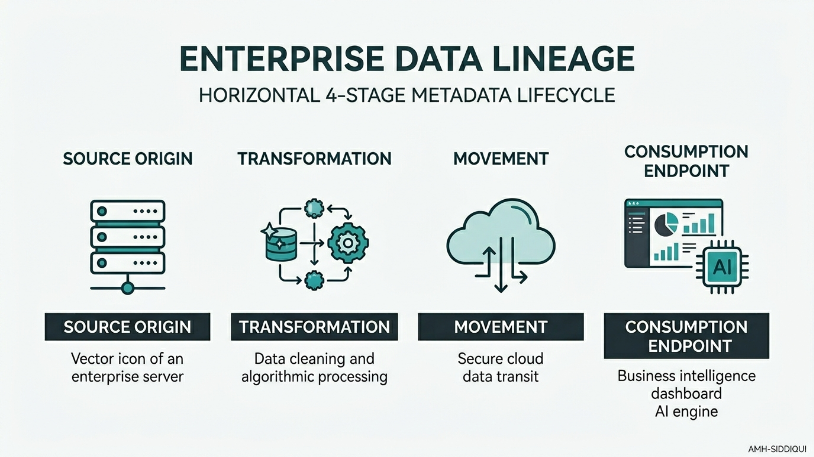
The Four Stages of the Data Journey
A mature data lineage framework tracks information through four distinct structural phases across the enterprise pipeline:
1. The Data Source Origin
The journey begins at the collection layer. This includes operational databases, transactional systems, enterprise resource planning (ERP) platforms, and incoming third-party data streams. Capturing accurate metadata at this entry point is vital for establishing baseline data quality.
2. The Transformation Stage
As data passes through data lakes and staging environments, it rarely stays raw. Systems clean, aggregate, filter, and combine data records to prepare them for business use. Lineage tools record these structural modifications to show the exact logic behind every calculated metric.
3. The Movement Phase
Enterprises routinely shift information across complex hybrid networks, shifting data from on-premises hardware to cloud storage repositories. Lineage monitoring tracks these system-to-system migrations, documenting data pathways and verifying delivery integrity.
4. The Consumption Endpoint
The final stage traces data directly to its ultimate business destination. This endpoint could be an executive financial dashboard, an automated regulatory compliance report, a customer-facing portal, or an active machine learning training set.
Strategic Operational Benefits for Enterprises
Accelerated Root Cause Analysis
When an anomaly appears in a Monday morning executive report, data teams typically waste hours hunting down the source of the error. Data lineage allows engineers to trace the flawed metric backward through the pipeline instantly, pinpointing the exact broken script or corrupted database entry within clicks.
Uncompromising Regulatory Compliance
Global data regulations require strict accountability regarding how customer data is processed and stored. Data lineage generates automated, verifiable audit trails. These blueprints show financial and healthcare regulators exactly how data moves across boundaries, significantly simplifying compliance reporting.
Ensuring Trustworthy AI and Model Auditing
An artificial intelligence model is only as safe as its training data. If a machine learning model starts outputting biased results or hallucinations, engineers must audit its inputs. Data lineage tracks the lifecycle of training sets, providing the structural visibility needed to run explainable, ethical AI initiatives.
Technical Hurdles to Lineage Implementation
| Operational Bottleneck | Impact on Data Infrastructure | Strategic Technical Solution |
| Siloed Data Environments | Fragmented legacy tools hide data flows from central views | Deploy automated, system-agnostic metadata harvesters |
| Lack of Schema Standardization | Inconsistent naming conventions across departments break tracking | Implement a unified enterprise data dictionary |
| Exponential Scale Velocity | High-volume streaming data quickly overwhelms manual logs | Integrate real-time, runtime lineage extraction tools |
Primary Governance Risks of Visibility Gaps
Operating a major enterprise data network without structured lineage mapping triggers a dangerous, cascading operational vulnerability. A lack of structural oversight allows undocumented adjustments to slip into upstream production environments completely unnoticed. This structural blind spot causes calculations to break silently in downstream dashboards, which ultimately forces business analysts to build strategic corporate choices on flawed, untrustworthy data.
Navigating Strategic Upstream Changes
In a highly connected system, a minor modification to a database column can trigger widespread issues downstream. Without data lineage, engineers cannot perform accurate impact analysis. A simple database field change can inadvertently break dozens of connected dashboards, reports, and production applications across the company.
Best Practices for Building Modern Lineage Programs
Deploying a successful enterprise data lineage initiative requires combining automated tools with clear operational policies:
- Mandate Automated Extraction: Avoid manual documentation processes, which become obsolete the moment code updates. Rely on automated tools that extract metadata directly from database logs, code repositories, and ETL tools.
- Merge with Core Data Governance: Treat lineage as an active extension of your broader data governance strategy. Link your data pipelines directly to data dictionaries and data catalogs to provide clear operational context.
- Enforce Strict Metadata Policies: High-quality lineage depends on clean metadata. Establish company-wide standards for code tags, schemas, and system descriptions to keep tracking smooth and consistent.
Related Readings:
- Data Governance Framework and Pillars
- Data Governance – How to Set a Strong Foundation?
- Data Governance Readiness Assessment
- What Is MDM (Master Data Management)?
- Navigating the Big Data Lifecycle: From Collection to Insight
- Big Data Security, Privacy, and Protection
- Big Data vs. Traditional Data, Data Warehousing, AI and Beyond
- Leveraging Big Data through NoSQL Databases
- AI (Artificial Intelligence) – Key Concepts
- What Is Integrated AI (Artificial Intelligence)?
- NIST AI RMF – A Momentary Look
- Six Essential Practices for Responsible AI Governance
- Attribute-Based Access Control (ABAC) – A Modern Approach to Dynamic and Granular Security
- Defense-in-Depth (DiD) Principle
- Zero-Knowledge Proof (ZKP) – A Professional Review
- How AI and IoT Are Driving Digital Transformation Across Industries
- Human Brain Vs Artificial Intelligence
- Bioinformatics and Artificial Intelligence
- Quantum Computing and Artificial Intelligence: The Next Technological Revolution
- Synthetic Data: The Future of AI Training Without Privacy Risks