
Introduction
Data is the foundational fuel of the modern enterprise, but acquiring it has become a legal and operational minefield. To build accurate machine learning models, engineers require massive, diverse datasets. Yet, the tightening grip of global compliance frameworks—such as GDPR and CCPA—means that collecting, storing, and processing real-world user information carries immense financial and regulatory risk.
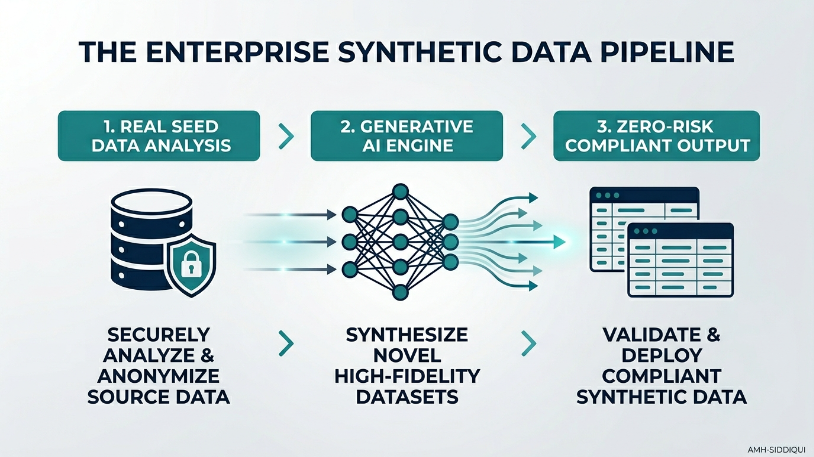
To break this bottleneck, data science teams are shifting toward a revolutionary alternative: synthetic data. By algorithmically fabricating entirely artificial datasets that perfectly mimic the mathematical properties of real-world information, organizations can train production-grade AI models. This breakthrough allows for rapid innovation while completely eliminating data privacy and confidentiality liabilities.
Defining Synthetic Data Architecture
Synthetic data is artificially generated information created using statistical models and machine learning algorithms rather than direct collection from human activities or physical events.
Unlike masked or anonymized data—which merely strips away explicit identifiers like names or social security numbers from real records—synthetic data is built entirely from scratch. It contains no traces of authentic user identities, yet it retains the exact statistical distributions, correlations, and behavioral patterns of the original source environment. This ensures that when an enterprise machine learning model trains on artificial data, its real-world predictive accuracy remains highly stable.
The Core Technical Methods of Generation
Engineers use three primary methodologies to manufacture high-fidelity synthetic datasets based on operational needs:
1. Advanced Statistical Modeling
Traditional generators analyze a baseline dataset to calculate its core mathematical properties, such as mean, variance, and standard deviation. The system then runs Monte Carlo simulations or probabilistic sampling to generate new, artificial data rows that adhere to those exact parameters.
2. Generative Adversarial Networks (GANs)
GANs use a highly effective two-part neural network architecture. A Generator network creates fake data samples, while a Discriminator network evaluates them against real-world data to spot differences. The two networks train against each other continuously until the artificial data is mathematically indistinguishable from the real dataset.
3. Variational Autoencoders (VAEs)
VAEs compress real enterprise data into a simplified, low-dimensional space. The network then decodes and expands that compressed map to reconstruct entirely new, unlinked data records that mirror the complex structural characteristics of the original information.
Strategic Advantages for Enterprise Data Pipelines
Complete Elimination of Privacy and Compliance Risks
Because synthetic records are not tied to real individuals, they bypass strict personal identifiable information (PII) regulations. This allows data teams to share, move, and analyze pipelines globally across multi-cloud environments without triggering compliance penalties.
Unlocking Data Accessibility and Velocity
Procuring, cleaning, and labeling real-world enterprise data can take months. Synthetic data pipelines allow developers to generate massive, structured datasets on demand, shortening AI development lifecycles from quarters to days.
Simulating Rare Edge Cases
Real-world data rarely captures extreme, catastrophic events frequently enough to train predictive models effectively. Synthetic environments give engineers the power to intentionally inject rare edge cases—such as highly sophisticated financial fraud patterns or uncommon medical anomalies—straight into the training mix.
Real-World Industry Implementations
| Industry Vertical | Real-World Data Constraints | Synthetic Data Use Case |
| Healthcare & Genomics | Protected health information (PHI) limits cross-border research collaboration | Generates synthetic patient records to train diagnostic models securely |
| Financial Services | Strict financial privacy laws block external penetration testing | Replicates realistic transactional streams to pressure-test fraud detection engines |
| Autonomous Driving | Physical testing on public roads is expensive, slow, and dangerous | Simulates millions of miles of synthetic edge-case driving environments |
| Smart Cities & IoT | Massive sensor arrays compromise regional pedestrian privacy | Simulates urban traffic flow and grid congestion patterns for infrastructure design |
Primary Limitations and Governance Risks
While synthetic data solves massive privacy bottlenecks, it requires rigorous validation and governance before being deployed into production systems.
Biased Real Data Algorithmic Replication Skewed Synthetic Output Flawed AI Models
The Threat of Inherited Algorithmic Bias
Synthetic generation models learn directly from real-world baselines. If an organization’s historical data contains human biases, structural inequalities, or missing segments, the generation engine will replicate and amplify those exact flaws in the synthetic output, leading to inaccurate AI decisions.
Maintaining Fidelity and Realism
If a generation model is tuned poorly, the synthetic data can lose the complex, underlying correlations found in the real world. This degradation creates an accuracy gap, resulting in an AI model that performs perfectly in the sandbox but fails completely when exposed to real human behavior.
High Initial Compute and Engineering Costs
Developing, tuning, and validating advanced generative models like GANs requires significant computing power and specialized data engineering talent. For many mid-sized enterprises, the upfront investment required to build reliable generation pipelines remains a barrier to entry.
The Integration into Responsible AI Strategies
As enterprise technology focuses heavily on trust, auditability, and safety, synthetic data is cementing its place as a core pillar of Responsible AI. By substituting sensitive personal records with simulated alternatives, companies can rigorously test their software for fairness, audit model reactions to edge cases, and eliminate data privacy concerns. When deployed alongside clear data management frameworks, synthetic data helps businesses innovate aggressively while remaining fully accountable to ethics boards and global regulators.
Related Readings:
- AI (Artificial Intelligence) – Key Concepts
- What Is Integrated AI (Artificial Intelligence)?
- NIST AI RMF – A Momentary Look
- Six Essential Practices for Responsible AI Governance
- Data Governance Framework and Pillars
- Data Governance – How to Set a Strong Foundation?
- Data Governance Readiness Assessment
- What Is MDM (Master Data Management)?
- Big Data Security, Privacy, and Protection
- Zero-Knowledge Proof (ZKP) – A Professional Review
- Attribute-Based Access Control (ABAC) – A Modern Approach to Dynamic and Granular Security
- Defense-in-Depth (DiD) Principle
- Human Brain Vs Artificial Intelligence
- Bioinformatics and Artificial Intelligence
- How AI and IoT Are Driving Digital Transformation Across Industries
- Threat of AI in Healthcare
- Internet of Things (IoT) Security
- future-of-remote-robotic-surgery