
Introduction
The current enterprise Artificial Intelligence boom has arrived with a sobering realization: deep learning models are fundamentally limited by the shape of the data they consume. Massive corporate data lakes are filled with unstructured text, isolated databases, and fragmented system logs. While modern AI applications excel at processing raw statistics at scale, they frequently fail to grasp the nuanced relationships and operational contexts that tie a business together.
Without a unified way to map real-world meaning, intelligent systems suffer from hallucinations, output biased results, and remain black boxes that executives cannot fully trust. To bridge this structural gap, data engineers are deploying knowledge graphs. This advanced data structure serves as the semantic nervous system of modern enterprise architecture, providing the explicit context required to build trustworthy, explainable AI.
What Is a Knowledge Graph?
A knowledge graph is a highly scalable, network-based data structure designed to capture, store, and link information based on real-world meaning. Unlike legacy relational databases that force data into rigid, isolated rows and columns, a knowledge graph treats the connections between data points as primary assets.
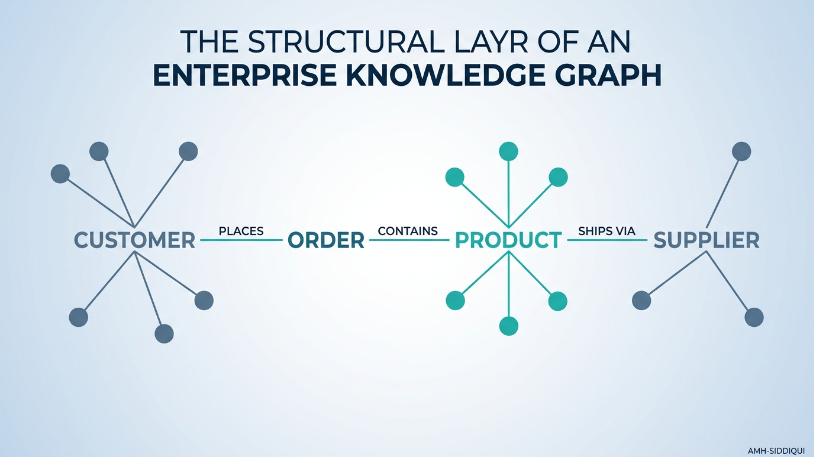
By mapping data as a web of interconnected entities, the system models information exactly how humans understand it. For instance, a customer record does not sit isolated in a customer relationship management (CRM) silo. Instead, it links explicitly to an order, which connects directly to a specific product catalog, which maps back to a regional supplier network. This interconnected architecture shifts focus from merely storing data values to active relationship mapping.
The Three Core Semantic Components
Every knowledge graph relies on a flexible, graph-based framework composed of three foundational elements:
1. Entities (Nodes)
Nodes represent the core objects within the business ecosystem. These can be physical assets like products, facilities, and employees, or conceptual structures like financial transactions, geographic locations, and cost centers.
2. Relationships (Edges)
Edges define the explicit, semantic nature of the connection between two nodes. Instead of relying on ambiguous database keys, edges use clear, directional statements such as Customer purchased Product, Supplier operates in Region, or Employee manages Department.
3. Attributes (Properties)
Properties represent the specific key-value descriptions attached to individual nodes or edges. This includes data elements like a product’s wholesale price, a customer’s account creation date, or the timestamp of a specific shipping delivery.
Why Traditional Data Silos Limit Enterprise AI
Traditional data warehouses and relational databases were built for transactional processing, not relational reasoning. This structural limitation creates four severe bottlenecks for modern AI workloads:
Chronic Data Siloing
Corporate information routinely fragments across distinct department systems. This fragmentation leaves data science teams struggling to assemble a complete view of operational workflows.
Absolute Absence of Deep Context
Standard rows and columns record isolated values perfectly, but they obscure the underlying business dependencies and context. This lack of visibility limits an AI’s ability to run advanced reasoning paths.
High Latency on Multi-Join Queries
Tracing complex relationships across disparate SQL tables requires highly complex, compute-heavy JOIN operations. These workloads regularly throttle server performance and slow down real-time business pipelines.
The Problem of Unexplainable AI Outputs
When an enterprise machine learning model outputs a predictive decision based on flat data files, tracing its mathematical reasoning path is nearly impossible. This lack of clarity creates serious risks for compliance, data privacy, and auditing teams.
How Knowledge Graphs Empower Enterprise AI Pipelines
Integrating a semantic layer into your artificial intelligence infrastructure directly addresses these compute and transparency challenges across four critical operational areas:
Powering True Semantic Search
Legacy enterprise search engines rely heavily on literal keyword matching, which frequently returns irrelevant documentation. Knowledge graphs enable semantic search by interpreting the actual intent, context, and structural relationships behind an organization’s internal queries.
Accelerating Data Integration and Unifying Master Data
Master Data Management (MDM) focuses on maintaining a single source of truth for core business data. Knowledge graphs naturally support MDM goals by mapping and unifying conflicting data schemas across CRM, ERP, and support ticket systems into a single semantic map.
Facilitating Fully Explainable AI (XAI)
When an AI application draws data directly from a verified knowledge graph, its reasoning path is fully trackable. Compliance officers can audit the explicit connections the system used to reach a specific financial or clinical conclusion, turning an opaque model into a transparent workflow.
Real-World Strategic Industry Applications
| Industry Domain | Legacy Data Management Hurdle | Knowledge Graph Implementation |
| Financial Services | Fraud rings bypass detection by hiding across isolated bank accounts | Maps hidden corporate links to uncover complex money laundering networks |
| Healthcare & Biotech | Medical journals, clinical trials, and patient charts sit in disconnected silos | Connects symptoms, genomic profiles, and drug structures to accelerate research |
| E-Commerce & Retail | Basic recommendation engines rely on simple, inaccurate user history | Delivers highly tailored product suggestions based on real-time behavior |
| Cybersecurity Operations | Security teams cannot trace cascading risks across complex enterprise cloud networks | Visualizes vulnerabilities, network assets, and active threat paths simultaneously |
Critical Challenges on the Path to Implementation
While the operational benefits of a semantic infrastructure are immense, enterprise data teams must prepare for major engineering challenges during deployment. The initial challenge begins with data complexity: extracting fragmented data elements out of unstructured legacy environments requires a heavy upfront data modeling and schema mapping effort.
Resolving Continuous Maintenance Demands
Enterprises operate in a state of constant change. New customers sign up, product inventories update, and corporate hierarchies shift daily. A knowledge graph must update its semantic relationships in real time, requiring robust, automated metadata harvesting pipelines to prevent data obsolescence.
Addressing the Specialization Talent Shortage
Building and managing a scalable knowledge graph demands highly specialized technical skills. Data engineers must be proficient in graph query languages like Cypher or SPARQL, and understand complex semantic web standards like RDF and OWL, which are rare skillsets in standard data science teams.
The Next Era of Graph-Driven Automation
The future of enterprise technology is moving toward an architecture where knowledge graphs and Large Language Models work in tandem, a design pattern known as Retrieval-Augmented Generation (RAG). By grounding generative AI models in a structured, verified knowledge graph, companies can eliminate AI hallucinations and ensure outputs are accurate and securely audited.
As automated relationship discovery tools become standard, the effort required to build and maintain these semantic networks will drop drastically, making knowledge graphs a fundamental competitive advantage for future-ready digital enterprises.
Related Articles:
- Data Governance Framework and Pillars
- Data Governance – How to Set a Strong Foundation?
- Data Governance Readiness Assessment
- What Is MDM (Master Data Management)?
- Navigating the Big Data Lifecycle: From Collection to Insight
- Big Data vs. Traditional Data, Data Warehousing, AI and Beyond
- Leveraging Big Data through NoSQL Databases
- AI (Artificial Intelligence) – Key Concepts
- What Is Integrated AI (Artificial Intelligence)?
- NIST AI RMF – A Momentary Look
- Six Essential Practices for Responsible AI Governance
- Zero-Knowledge Proof (ZKP) – A Professional Review
- Attribute-Based Access Control (ABAC) – A Modern Approach to Dynamic and Granular Security
- Big Data Security, Privacy, and Protection
- Synthetic Data: The Future of AI Training Without Privacy Risks
- Quantum Computing and Artificial Intelligence: The Next Technological Revolution
- Bioinformatics and Artificial Intelligence