
Introduction
The rapid expansion of enterprise Artificial Intelligence has brought deep learning capabilities to almost every major business sector. However, this massive algorithmic growth has collided with an equally intense global tightening of data privacy, security, and corporate compliance regulations. Traditionally, building a highly accurate machine learning model required centralizing raw data assets into a single massive repository, cloud warehouse, or data lake for training.
This centralized approach creates significant vulnerabilities. Consolidating sensitive customer records, financial histories, or protected healthcare information into a single cloud environment establishes an incredibly high-value target for cyberattacks. Furthermore, rigid compliance frameworks like GDPR and CCPA heavily restrict or entirely ban the cross-border movement of personal data. To bypass this centralization bottleneck, enterprise data architects are utilizing federated learning. This privacy-preserving framework reverses the traditional data pipeline, allowing artificial intelligence models to learn from decentralized data stores without moving the underlying information.
Defining Federated Learning Architecture
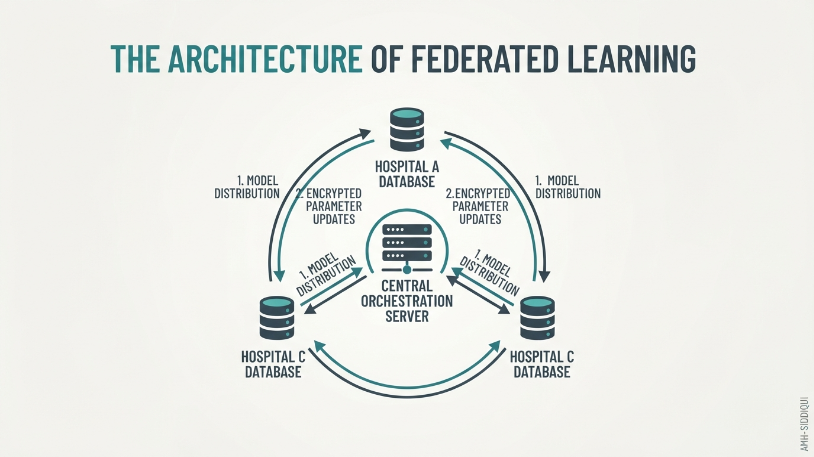
Federated learning is a decentralized machine learning training technique that allows an enterprise AI model to learn collectively from multiple distributed databases, edge devices, or local servers while keeping all source data localized.
Instead of moving raw data files across networks to a central processing hub, the base machine learning model travels to the data source. The training happens entirely within the local infrastructure. Once a local training cycle concludes, the system extracts the newly adjusted mathematical parameters—known as model updates or gradients—and sends only that metadata back to a central server. This operational model shifts the entire machine learning paradigm: the algorithm goes to the data, rather than the data going to the algorithm.
The Five-Stage Federated Lifecycle
A production-grade federated learning environment processes algorithmic training across five continuous, highly structured operational phases:
1. Initial Model Initialization
A centralized enterprise server establishes a foundational, untrained or semi-trained base artificial intelligence model tailored to the target business objective.
2. Decentralized Model Distribution
The central hub broadcasts copies of the base model across a secure network to a series of distributed edge devices, localized databases, or regional corporate servers.
3. Local In-Situ Training
Each local node ingests the base model and trains it using only the raw data natively available within its independent silo. The source information never leaves the local security boundary.
4. Gradient Transmission and Update Uploads
Once local optimization completes, the nodes strip away the data layer and package the updated mathematical weights. These specific parameter changes are transmitted back to the central orchestration server.
5. Secure Aggregation and Redistribution
The central server runs specialized consolidation algorithms, such as Federated Averaging, to merge the disparate node updates into a single, highly optimized global model. This updated global framework is then redistributed to the nodes, starting the iterative optimization loop again.
Addressing the Limitations of Centralized Systems
Relational data lakes and global warehouses face heavy strategic friction when feeding modern, distributed machine learning workloads:
High Network Latency and Bandwidth Costs
Shifting multi-terabyte datasets across cloud networks continuously introduces immense bandwidth overhead and bottlenecks real-time computational performance.
Extreme Compliance Constraints
Highly regulated industries like banking and healthcare operate under strict statutory barriers that penalize unauthorized personal data migration, stalling centralized AI initiatives.
Expanded Central Attack Surfaces
Consolidating proprietary datasets, operational metadata, and customer identities into a single infrastructure node creates an attractive, high-vulnerability target for malicious entities.
Strategic Operational Advancements Across Industries
| Industry Domain | Centralized Data Bottleneck | Federated Learning Implementation |
| Healthcare & Genomics | Patient privacy laws prevent different hospitals from pooling clinical records | Trains diagnostic models collectively across global medical networks without exposing patient charts |
| Financial Services | Regional compliance rules block international branches from sharing transaction logs | Identifies complex global fraud patterns by aggregating model parameters rather than raw histories |
| Smart Mobile Hardware | Sending personal user text inputs to cloud servers violates digital consumer privacy | Powers predictive text and localized voice assistants directly on edge smartphones |
| Industrial Internet (IoT) | Remote manufacturing facilities generate high-volume data too massive to upload | Optimizes predictive maintenance models locally on edge factory sensors in real time |
Critical Challenges and Governance Bottlenecks
While decentralized training offers immense architectural advantages, deploying a robust federated framework introduces complex software engineering and structural hurdles. The initial challenge begins with communication complexity: coordinating thousands of distinct edge devices or distributed regional servers requires significant network orchestration, as inconsistent connection speeds and dropouts can delay the global model aggregation cycle.
Distributed Nodes ---> Inconsistent Network Speeds ---> Delayed Weight Collection ---> Slower Aggregation
Navigating Device and Data Heterogeneity
Distributed nodes routinely operate on entirely different hardware profiles, featuring variable processing power, memory availability, and storage capacities. Furthermore, local datasets are often non-identically distributed (Non-IID), meaning the data volumes and characteristics vary wildly from node to node, which can introduce mathematical bias into the global model.
Managing Advanced Security Vulnerabilities
While raw data remains safely isolated, federated learning is not automatically immune to cyber threats. Sophisticated attackers can perform model poisoning attacks by injecting corrupted training updates from a compromised node, or use reverse engineering techniques to infer details about the underlying local data simply by analyzing the transmitted gradient updates. Defending against these risks requires layering advanced cryptographic tools, such as differential privacy and secure multi-party computation, directly onto the pipeline.
The Future of Privacy-First Data Governance
The long-term trajectory of enterprise technology relies on the complete unification of federated learning, edge computing, and zero-trust security frameworks. As organizations prioritize data sovereignty, federated ecosystems will become the foundational infrastructure for cross-company and cross-border research collaborations. By allowing enterprises to unlock the full analytical value of their distributed data networks without compromising consumer trust or regulatory compliance, federated learning is establishing a secure, decentralized foundation for modern enterprise intelligence.
Related Readings:
- AI (Artificial Intelligence) – Key Concepts
- What Is Integrated AI (Artificial Intelligence)?
- NIST AI RMF – A Momentary Look
- Six Essential Practices for Responsible AI Governance
- Synthetic Data: The Future of AI Training Without Privacy Risks
- Data Governance Framework and Pillars
- Data Governance – How to Set a Strong Foundation?
- Data Governance Readiness Assessment
- Data Lineage: The Missing Link in Modern Data Governance
- Knowledge Graphs: The Hidden Foundation of Enterprise AI
- Big Data Security, Privacy, and Protection
- Zero-Knowledge Proof (ZKP) – A Professional Review
- Attribute-Based Access Control (ABAC) – A Modern Approach to Dynamic and Granular Security
- Bioinformatics and Artificial Intelligence
- CRISPR and AI: How Intelligent Gene Editing Is Shaping the Future of Medicine
- The Rise of Organoids: Revolutionizing Drug Discovery and Personalized Medicine
- Threats of AI in Healthcare Data Management